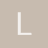Tamaño de la muestra para población infinita
Estoy realizando un proyecto para residenciarme de Ing. Industrial, el proyecto lo estoy realizando en una industria dedicada a la fabricación de papel y éste consiste en disminuir el desperdicio que es generado por el equipo que maneja las bobinas de papel, (Las bobinas de papel son la forma del producto semielaborado), este desperdicio no se encuentra calculado, por lo que si hago mejoras para la disminución de este desperdicio, necesito tener cuanto es el desperdicio actual para compararlo con el desperdicio que se obtiene con las mejoras. Considero que la población es infinita porque la producción de bobinas de papel es constante, los 7 días de la semana las 24 horas del día.
Encontré una fórmula para el calculo del tamaño de la muestra de una población infinita, pero existe un dato "P" = Prevalencia esperada del parámetro a evaluar en caso de desconcerse se aplica la opción más desfavorable 0.5.
Nota: De la población no se conoce ningún parámetro.
Entonces, Necesito saber si para mi caso esta fórmula aplica y de ser así el dato "P" que significa para mi caso.
De no aplicar esta fórmula, que fórmula podría utilizar.
Cualquier cosa adicional que necesite saber puede comunicarse conmigo a través de esta vía.
Encontré una fórmula para el calculo del tamaño de la muestra de una población infinita, pero existe un dato "P" = Prevalencia esperada del parámetro a evaluar en caso de desconcerse se aplica la opción más desfavorable 0.5.
Nota: De la población no se conoce ningún parámetro.
Entonces, Necesito saber si para mi caso esta fórmula aplica y de ser así el dato "P" que significa para mi caso.
De no aplicar esta fórmula, que fórmula podría utilizar.
Cualquier cosa adicional que necesite saber puede comunicarse conmigo a través de esta vía.
1 respuesta
Respuesta de therion_bcn
1